Cluster Analysis
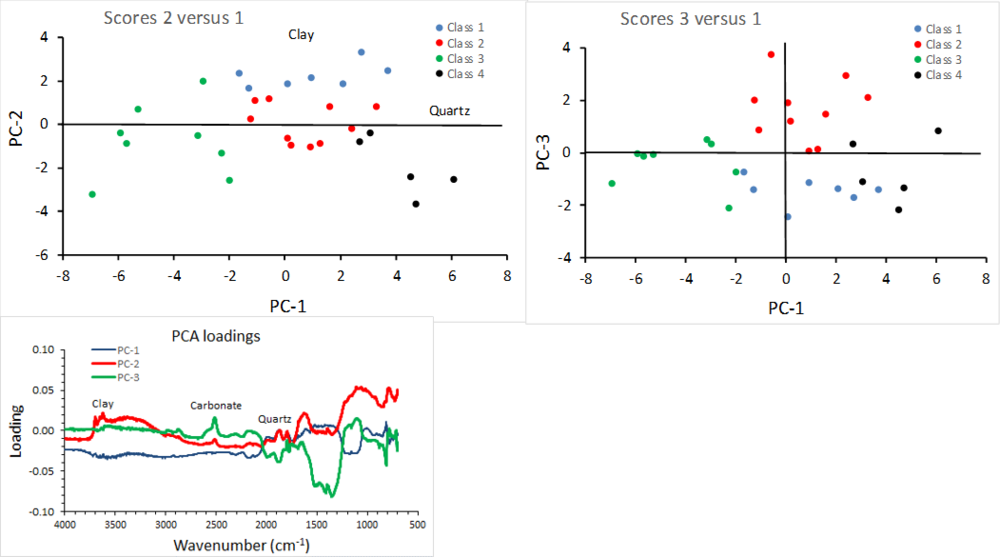
Cluster analysis is used for grouping soils with similar properties. The clusters are determined using principal components analysis (PCA) scores and describe the relative distribution of soils with similar or dis-similar compositions or soil types. The scores are related to corresponding loadings which represent the soil compositions characteristic of the soil set.
 1. Important samples are selected by Kennard-Stone (KS) algorithm
1. Important samples are selected by Kennard-Stone (KS) algorithm
2. Principal Component Analysis (PCA) carried out to determine scores and loadings
3. Apply PCA and K-means clustering to determine groupings within the score space.
4. The loadings show MIR peaks related to soil components
Execution
The calibration sub-samples from the Kennard-Stone (KS) selection represent the entire sample set based on the maximum variability of the PCA scores. In operation, the required number of sub-samples and principal components are input into the selection algorithm. The algorithm selects the required calibration subset from scores of all the samples.
Used in
Read more |
Read also |
|
Deliverable 7.2 Deliverable 7.4 Milestone 6 |
Janik LJ, et al. (2009). Chemometrics and Intelligent Laboratory Systems 97, 179–188 |
Contact
 Les Janik
Les Janik
CSIRO
Email: Les.Janik@csiro.au